5 . Inverting the Test Automation Pyramid
Small is Beautiful, Cheap is Good and Cultural Change Matters
By Martin Ivison
SUMMARY
A growing company was tasked to develop a test automation program from scratch, change its coding practices, and build a continuous testing toolchain. Martin Ivison details how they did it, including realizing that implementing the traditional test pyramid was not going to work—it would have to be turned upside down. They found out that small is beautiful, cheap is good, and cultural change matters.
“Robofy us.”
The story I heard in my job interview was common yet intriguing: The company had grown from a one-man basement operation to be the market leader in direct-to-consumer sales for wineries.
But with well over $1 billion of transactional volume flowing through every year, the company’s system had developed chronic pains in architecture, infrastructure, and code quality.
What is more, any progress was limited by a bottleneck of a single person testing everything by hand.
I was asked to build out a functioning QA unit and start the company on a test automation program. Two years in, we can now take stock and share our experiences.
What we found out is that small is beautiful, cheap is good, and cultural change matters.
The Vision
While there were some pressing problems to deal with, we first spent some time talking about the long-term goals for test automation to make sure that we would be running in the right direction.
As a steadily growing company in a competitive field, we were naturally gunning for speed, flexibility, and scalability. But in more concrete terms, we needed to consider two very different factors for the buildout: the technical angle and the cultural angle.
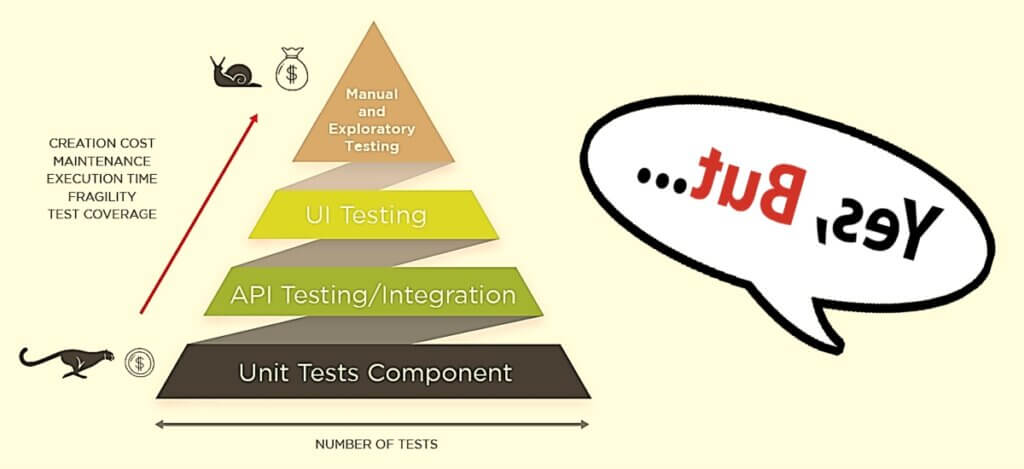
Technically, we envisioned three-tiered test automation —unit, integration, and system testing— with a loosely coupled chain of low-cost tools embedded in a continuous integration and deployment flow.
The non-technical angle was arguably harder: We needed to introduce a culture of developers testing their own code and of product owners investing in the time to build out frameworks. We also needed a QA team that could foster and drive an end-to-end quality process in the working Agile teams, while being able to code and build out additional tools.
What we were emphatically not trying to do was eliminate manual testing. Instead, we would be focusing our testing minds on high-value activities such as evaluating prototypes and testing through complex scenarios—and, of course, freeing up testers to automate.
Starting from very near scratch, we understood that what we were setting out to do was going to be a multi-year journey.
Ground Zero
The initial conditions were encouragingly bleak. The majority of the system rested on some 1.5 million lines of legacy ColdFusion code without any unit or integration tests.
Code changes were system tested manually on a local machine, merged to master, and deployed nightly straight into production without further testing.
Production health was monitored with pings and some bare-bones scripted tests for web services.
And while the team had started branching out into more modern frameworks (including Rails, Angular, Node, and Serverless), using framework-native testing capabilities was still in its infancy.
Pondering the options, it became clear that we would have to work down—or invert—the testing pyramid.
While ordinarily testing capabilities are built bottom-up with the code (write unit tests, then integrate and write integration tests, then integrate further and write system tests), we were working with an existing, testless system.
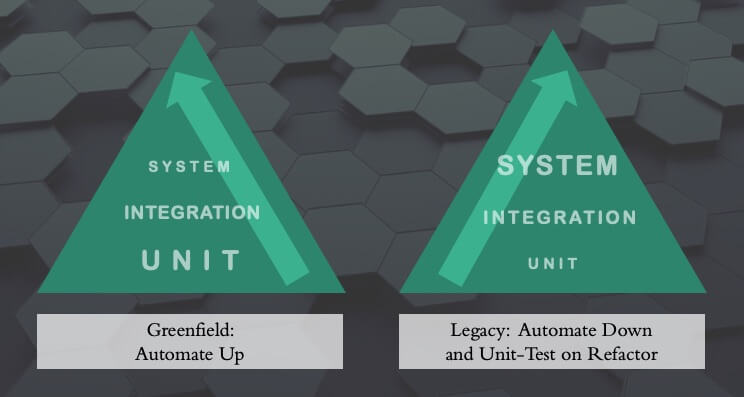
To mitigate risk progressively, we would have to start at the top—the system level—and backfill the lower rungs later, relying on that all-important culture change.
The principal risk, in our case, was posed by the testless nightly deploys of our production platform. As we could not embed the tests in the legacy code, we had to create an independent test application that could monitor the entire system’s vital functions.
This minimum viable product (MVP) suite covered our major, revenue-generating business flows and apps (orders, shopping cart, point of sale, and club processing).
It was Selenium-based and written in Ruby, leveraging SitePrism for page-object management and Capybara. Tests ran on BrowserStack and were scheduled to run post-deploy and at various times during the day from Jenkins.
This first line of defense was running in production within three weeks, and we reached the envisioned coverage to minimize our business risk by the end of three months—about two hundred hours of effort.
Getting Traction: APIs
Our next objective was to start testing APIs. Testing on this level would be more robust and would allow us to broaden our coverage with a much lower need for test maintenance.
As a stroke of luck, a high percentage of our system communicates with or responds to basic HTTP calls.
Using Postman, we found that we could simulate the business flows of many of our core apps almost entirely. With JavaScript, we scripted the tests to create their own data and flexibly work in any environment.
With our eyes still first and foremost on production, we used Postman Monitors to run continuously scheduled production tests, which seamlessly integrated with our DevOps tools (VictorOps, Github, Jira and Slack).
This move had additional benefits. For one, we were able to use the HTTP call flows from Postman to quickly model and build JMeter load tests for our apps, which we could use to test from BlazeMeter on demand. For low additional effort, we had created the beginnings of a performance test capability.
Secondly, as we trained and hired new QA staff, the low barriers on JS in Postman made it the perfect entrance technology for our testers to learn how to write automation code.
It also quickly established a common language between QA and developers. We both understood the integration layers and worked hand-in-hand to automate them.
This also facilitated the conversation about our lack of unit tests and encouraged developers to take action to refactor convoluted code and grow code quality.

Thirdly, we opened up strategic possibilities for a future continuous integration and delivery (CI/CD) process. Both Postman (via its CLI-twin Newman) and our Ruby Selenium tests could be run from continuous delivery tools such as CircleCI or AWS CodePipeline alongside our budding unit tests.
This milestone marked the end of a year, during which we saw a continuous decline in reported production bugs.
The fixed cost at this point was the outlay for two additional employees in QA, and a negligible amount in tooling.
Year Two: An E2E Chain
Year two saw us tackle our greatest obstacle: the platform code monolith. Because the platform was essentially many apps with different needs rolled into one big stack, deploying it was a complex process that could not be done on the fly.
To address this, we kicked off two initiatives: separating front ends from a shared back end through a new API layer; and pushing to containerize the components with Docker, integrate them with CircleCI, and deploy them fluidly with Amazon EKS.
For the new API layer, we refactored the code to cleanly separate the front ends and back end.
This had the immediate benefit that we could now test it with our existing API tools and grow our coverage rapidly. We could also insert new testing tools and methods. The refactor was made safer by adding linting (Codacy) and unit test frameworks (Testbox for ColdFusion), and by making the unit tests mandatory for each code change.
The front ends, meanwhile, were replatformed on Angular. This meant that we could now use embedded testing frameworks for both unit and integration tests (Mocha, Chai and Protractor).
Here, we further capitalized on those all-important cultural benefits: Based on our JS experience in Postman, the QA team was able to ease into ownership and scripting of those tests.
After two years of effort, the bug signal from production has fallen to marginal levels without any additional fixed cost. Opening all our apps to CI/CD, on the other hand, has enabled us to rethink test environments and opened the door for fully continuous testing in year three.
The vision is to use our growing collection of application containers to start spinning up tailored environments for automated testing. The deployment toolchain can then channel all changes so that the impact radius of the change and the associated risk determine the volume and breadth of the testing on it.
The idea is that our three-tiered test coverage now allows us to promote simple changes straight to production, while riskier changes would divert into staging environments for deeper manual tests and our newly developed load tests.
Building the Inverted Pyramid
With the end in view, we can look back on a number of critical things we learned as a team in building this inverted pyramid.
Because we did not have the opportunity to build it the right way up, we had to start at the tip and hope that the building blocks below would move to fit in the new process as we drove down.
This is hardly possible without the buy-in and continuous learning of the team, which makes the cultural aspect of such change all-important.
We managed this by creating a common playground for dev and QA in the integration layer, and by speaking a common language with JavaScript. This helped radiate mindsets and practices in both directions and was integral to developing a continuous testing process.
Further, as in any project endeavor, it helps to have a keen eye for risk, value, and maintenance cost.
For system-level tests, we secured the money-making flows in production first with a relatively small suite (fewer than twenty scenarios), and then stopped there, as GUI tests are notoriously brittle and expensive to maintain. We filled in the more robust lower-rung tests later as we built out API layers, added frameworks, and refactored the code.
Finally, we found that in the age of easily integrated tools, it is a perfectly viable strategy to go cheap.
We strung low-cost tools into loosely coupled chains in which pieces were added incrementally for a growing capability map, rather than looking for the single committed solution upfront. The majority of our tools are open source, and the remainder are cloud-based services that are easily switched out when competitors offer a more cost-effective solution.
As with all testing endeavors, there is no one-size-fits-all solution. Having buy-in from the teams is essential, because when everyone understands and supports the overall goals, they will figure out the best way to get there—even if it means turning traditional practices upside down.
I am Martin Ivison and these are my agile-thoughts
2025 © Vancouver, British Columbia, CANADA by Martin Ivison

Martin is a software test professional, former long-haired rock star, erstwhile science fiction author, avid rock climber, full time student of humanity and holder of no degrees.
A far-thinking, conscientious coder with an eye for meaningful improvements who speaks English and German. His focus is on E2E Quality Assurance, Test Leadership, Test automation, and QA Service & Practice Development.
Author of “Risk-Driven Agile Testing: A primer on how risk-based thinking drives lean and effective software testing” and lives and works in Vancouver, Canada.
Did you like it?